Skalierung auf mehreren Rechnern¶
Dieses Dokument wird die Referenzarchitektur aufzeigen die ownCloud skaliert und welches Modell für eine einzelne Datencenter-Implementierung verwendte wird. Das Dokument bezieht seinen Fokus auf die drei Hauptelemente die ownCloud einsetzt:
- Applikation layer
- Datenbank Layer
- Speicherplatz Layer
In jeder Schicht ist es das Ziel, die Möglichkeit zur Skalierung bereitzustellen, bei gleichzeitig hoher Verfügbarkeit und Aufrechterhaltung des dafür erforderlichen Leistungsniveaus.
Applikation Layer¶
Für die Anwendungsschicht der Referenzarchitektur wird Oracle verwendet mit Enterprise Linux als Front-End-Server, um den ownCloud Code zu hosten. In diesem Beispiel haben wir eine permissive-Domäne verwendet die es ermöglicht, das diese innerhalb einer SELinux-Umwelt einen Betrieb per httpd durchzuführen. Auch in diesem Beispiel verwendeten wir die Standardverzeichnis strukturen, indem der ownCloud Code in das Apache-Stammverzeichnis geschrieben wird. Die Folgende Komponenten, sind auf jedem Anwendungsserver installiert:
- Apache
- PHP 5.4.x
- PHP-GD
- PHP-XML
- PHP-MYSQL
- PHP-CURL
- SMBCLIENT
Es ist auch erwähnenswert, dass die entsprechenden Ausnahmen, die wir in der Fireall gemacht haben, um den Datenverkehr von ownCloud zu überprüfen (für die Zwecke der Prüfung erlauben wir das ermöglichen sowohl verschlüsselte SSL über Port 443 und unverschlüsselt über Port 80) entsprechend notwenidig sind.
Der nächste Schritt war notwendig, um die benötigten SSL-Zertifikate zu erzeugen und zu importieren, dabei werden die Standard-Verfahren in der OEL-Dokumentation verwendet.
Der nächste Schritt besteht darin, eine skalierbare Umgebung in der Anwendungsschicht zu erzeugen, das stellt die Load-Balance her. Weil die Anwendungsserver hier Staatenlos sind, wird das einfach über die Konfiguration und replizieren (einmaliger Speicherung und Datenbankverbindungen konfiguriert) und der Platzierung hinter einem Last Balancer in einer skalierbaren und hochverfügbaren Umgebung erstellt. Zu diesem Zweck haben wir uns für HAProxy entschieden und konfigurieren diesen für HTTPS-Datenverkehr nach der Dokumentation, zu finden Sie unter http://haproxy.1wt.eu/#doc1.5
Es ist erwähnenswert, dass diese besondere Load Balancer nicht erforderlich ist, wenn die Verwendung von einem kommerziellen Load Balancer (z.Bsp F5) hier genutzt werden soll. Es ist auch erwähnenswert, dass der Server, auf denen HAProxy Setup mit einem Überwachsunsginal und IP-Shift-Failover läuft verwendung einer IP-Adresse scheitern sollte.
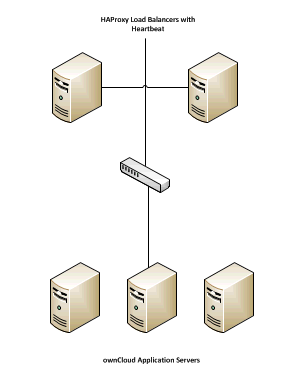
Datenbank Layer¶
Für die Zwecke dieses Beispiels haben wir einen MySQL-Cluster mit der NDB Speicher-Engine gewählt. Der Cluster wurde, auf der Grundlage der hier gefundenen Dokumentation http://dev.mysql.com/doc/refman/5.1/en/mysql-cluster.html, so konfiguriert, das er wie folgt folgt aussieht:
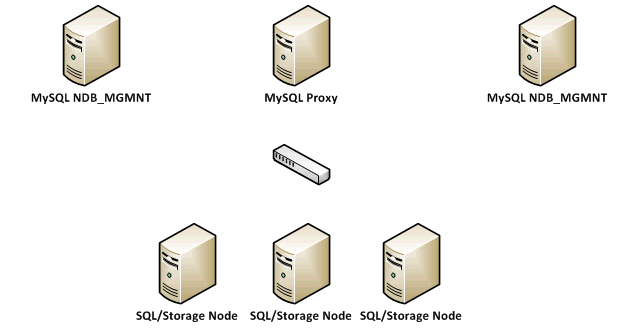
Ein genauerer Blick auf die Datenbank-Architektur haben wir einen redundanten MySQL NDB Management-Knoten erstellt und wir haben 3 NDB SQL / Storage-Knoten konfiguriert, über die wir in der Lage sind, den Datenbank-Verkehr zu verteilen. Alle Clienten die (ownCloud Application Servers) sich mit der Datenbank vi verbinden, verwenden den My SQL Proxy. Es ist erwähnenswert, dass MySQL Proxy noch im Betastadium ist, mit einem anderen Lastausgleichsverfahren wie HAProxy oder F5 wird unterstützt, in dass Sie den Verkehr zwischen den verschiedenen SQL / Storage-Knoten verteilen können. Hier haben wir einfach einen Swap-MySQL Proxy für eine richtig konfigurierte HAProxy und das Folgende verwendet:

In diesem Beispiel haben wir auch einen zweite HAProxy Server mit Heartbeat verwendet, um jede einzelne Fehlerquelle zu vermeiden. Wir haben auch NIC Bindung implementiert, um Lastenausgleich für den Datenverkehr auf mehrere physische Netzwerkkarten zu verteilen.
Speicherplatz Layer¶
Speicher wurde mit dem Red Hat Storage Server mit den GlusterFS Einsatz (als Teil des Red Hat Storage Server Angebot vorkonfiguriert) realisiert.
Der Red Hat Storage Server wurde entsprechend konfiguriert, wofür als Basis die Dokumentation verwendet wurde die Sie hier finden https://access.redhat.com/site/documentation/en-US/Red_Hat_Storage/2.0/html/Administration_Guide/Admin_Guide_Part_1.html
Für die Zwecke der Skalierung und der hohe Verfügbarkeit haben wir ein verteiltes repliziertes Volumen mit IP Fail Over knfiguriert. Das Konfigurieren der Speicherung erfolgt auf einem separaten Subnetz mit gebundenen Netzwerkkarten auf der Anwendungsserverebene. Wir haben den Speicherplatz mit NFS und für eine hohe Verfügbarkeit ausgewählt und haben den IP Failover des Speichers, wie hier dokumentiert https://access.redhat.com/site/documentation/en-US/Red_Hat_Storage/2.0/html/Administration_Guide/ch09s04.html impementiert.
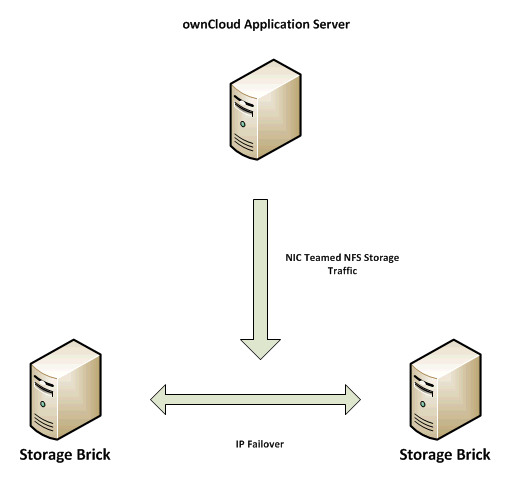
Wir haben uns für das bereitstellen des Speichers in dieser Weise sowohl für HA und Adresse die Erweiterbarkeit des Speichers sowie die Verwaltung Performance durch einfaches Hinzufügen weitere Bausteine zu dem Speichervolumen durch zusätzliche physikalische Platten entschieden.
Es ist erwähnenswert, dass verschiedene Möglichkeiten für die Speicherkonfiguration vorhanden (Wie gestreift replizierte Volumes) sind. Eine Diskussion welche Art von IO Leistung erforderlich ist und für die dafür benötigten HA-Konfiguration Platz zu schaffen, wurde das als die bestmögliche Option verstanden.
Hinzufügren weiterer Teile:
Wenn wir Teile hinzufügen, haben wir die folgenden dafür verwendet:
- Eine Anwendungsschicht, die dynamische Expansion unterstützt durch das Hinzufügen von zusätzlichen Servern ermöglich und HA hinter einem Load Balancer anbietet
- Ein Datenbankschicht, die auch durch den Zusatz von weiteren SQL / Storage-Knoten skaliert werden kann und die HA hinter einem Load Balancer bereitstellen wird
- Ein Speicherschicht, die dynamisch zu erweitern ist, um Speicheranforderungen zu erfüllen, wird auf Backend-Hardware-basierte Skalierung eingesetzt und HA über IP-Failover angeboten
